BisenetFormer#
Overview#
BisenetFormer is an advanced segmentation model that combines the efficiency of BiSeNet (Bilateral Segmentation Network) with the power of transformer architectures. Developed by FocoosAI, this model is designed for real-time semantic segmentation tasks requiring both high accuracy and computational efficiency.
The model employs a dual-path architecture where spatial details are preserved through one path while semantic information is processed through another, then fused with transformer-based attention mechanisms for superior segmentation performance.
Neural Network Architecture#
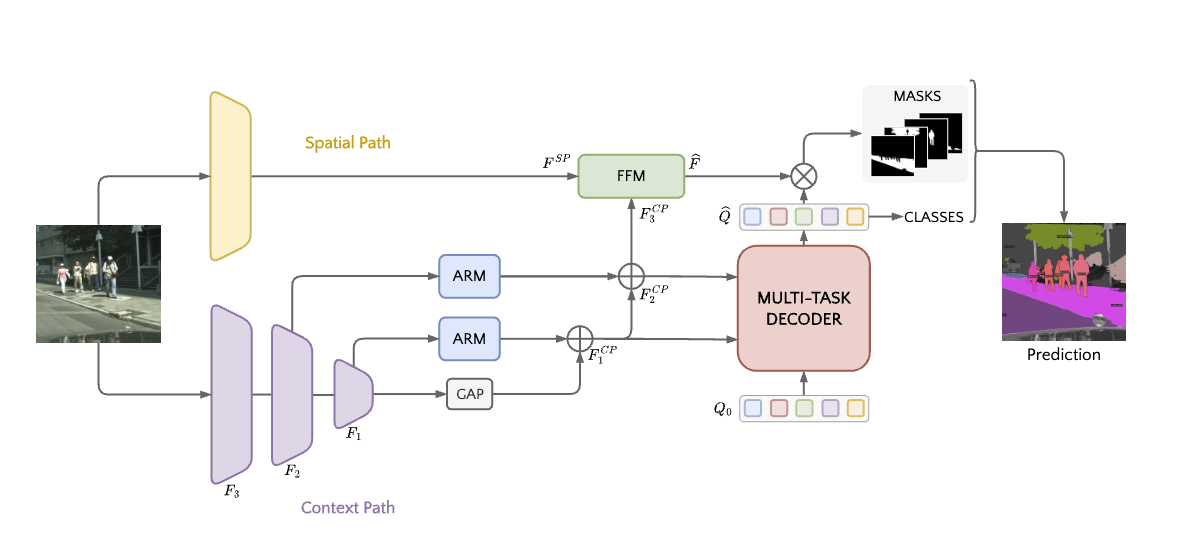 The BisenetFormer architecture consists of four main components working in concert:
The BisenetFormer architecture consists of four main components working in concert:
Backbone#
- Purpose: Feature extraction from input images
- Design: Configurable backbone network (e.g., ResNet, STDC)
- Output: Multi-scale features at different resolutions (1/4, 1/8, 1/16, 1/32)
Context Path#
- Component: Global context extraction path
- Features:
- Attention Refinement Module (ARM) for feature enhancement
- Global Average Pooling for context aggregation
- Multi-scale feature fusion with upsampling
- Purpose: Captures high-level semantic information
Spatial Path (Detail Branch)#
- Component: Spatial detail preservation path
- Features:
- Bilateral structure maintaining spatial resolution
- ConvBNReLU blocks for efficient processing
- Feature Fusion Module (FFM) for combining paths
- Purpose: Preserves fine-grained spatial details
Transformer Decoder#
- Design: Lightweight transformer decoder with attention mechanisms
- Components:
- Self-attention layers for feature refinement
- Cross-attention layers for multi-scale feature integration
- Feed-forward networks (FFN) for feature transformation
- 100 learnable object queries (configurable)
- Layers: Configurable number of decoder layers (default: 6)
Configuration Parameters#
Core Model Parameters#
num_classes(int): Number of segmentation classesnum_queries(int, default=100): Number of learnable object queriesbackbone_config(BackboneConfig): Backbone network configuration
Architecture Dimensions#
pixel_decoder_out_dim(int, default=256): Pixel decoder output channelspixel_decoder_feat_dim(int, default=256): Pixel decoder feature channelstransformer_predictor_hidden_dim(int, default=256): Transformer hidden dimensiontransformer_predictor_dec_layers(int, default=6): Number of decoder layerstransformer_predictor_dim_feedforward(int, default=1024): FFN dimensionhead_out_dim(int, default=256): Prediction head output dimension
Inference Configuration#
postprocessing_type(str): Either "semantic" or "instance" segmentationmask_threshold(float, default=0.5): Binary mask thresholdthreshold(float, default=0.5): Confidence threshold for detectionstop_k(int, default=300): Maximum number of detections to returnuse_mask_score(bool, default=False): Whether to use mask quality scorespredict_all_pixels(bool, default=False): Predict class for every pixel, usually better for semantic segmentation
Losses#
The model employs three complementary loss functions as described in the Mask2Former paper:
- Cross-entropy Loss (
loss_ce): Classification of object classes - Dice Loss (
loss_dice): Shape-aware segmentation loss - Mask Loss (
loss_mask): Binary cross-entropy on predicted masks
Supported Tasks#
Semantic Segmentation#
- Output: Dense pixel-wise class predictions
- Use Cases: Scene understanding, autonomous driving, medical imaging
- Configuration: Set
postprocessing_type="semantic"
Instance Segmentation#
- Output: Individual object instances with masks and bounding boxes
- Use Cases: Object detection and counting, robotics applications
- Configuration: Set
postprocessing_type="instance"
Model Outputs#
Internal Output (BisenetFormerOutput)#
masks(torch.Tensor): Shape [B, num_queries, H, W] - Query mask predictionslogits(torch.Tensor): Shape [B, num_queries, num_classes] - Class predictionsloss(Optional[dict]): Training losses including:loss_ce: Cross-entropy classification lossloss_mask: Binary cross-entropy mask lossloss_dice: Dice coefficient loss
Inference Output (FocoosDetections)#
For each detected object:
bbox(List[float]): Bounding box coordinates [x1, y1, x2, y2]conf(float): Confidence scorecls_id(int): Class identifiermask(str): Base64-encoded binary masklabel(Optional[str]): Human-readable class name
Available Models#
Currently, you can find 3 bisenetformer models on the Focoos Hub, all for the semantic segmentation task.
| Model Name | Architecture | Dataset | Metric | FPS Nvidia-T4 |
|---|---|---|---|---|
| bisenetformer-l-ade | BisenetFormer (STDC-2) | ADE20K | mIoU: 45.07 mAcc: 58.03 |
- |
| bisenetformer-m-ade | BisenetFormer (STDC-2) | ADE20K | mIoU: 43.43 mACC: 57.01 |
- |
| bisenetformer-s-ade | BisenetFormer (STDC-1) | ADE20K | mIoU: 42.91 mACC: 56.55 |
- |
Example Usage#
Quick Start with Pre-trained Model#
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Custom Model Configuration#
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |